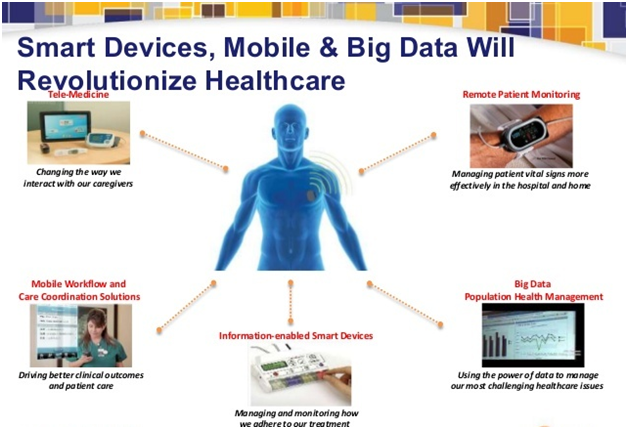
Apa itu Cloud Computing?
Cloud computing adalah penyampaian berbagai layanan melalui internet. Sumber daya ini termasuk alat dan aplikasi seperti penyimpanan data, server, database, jaringan, dan perangkat lunak. Daripada menyimpan file di hard drive milik atau perangkat penyimpanan lokal, penyimpanan berbasis cloud memungkinkan untuk menyimpannya ke basis data jauh. Selama perangkat elektronik memiliki akses ke web, ia memiliki akses ke data dan program perangkat lunak untuk menjalankannya. Komputasi awan adalah pilihan populer untuk orang dan bisnis karena sejumlah alasan termasuk penghematan biaya, peningkatan produktivitas, kecepatan dan efisiensi, kinerja, dan keamanan.
Manfaat Komputasi Awan
Dari penjelasan tentang cloud computing diatas, ada banyak manfaat yang bisa kita ambil dari cloud computing, yaitu :
- Skalabilitas, yaitu dengan cloud computing kita bisa menambah kapasitas penyimpanan data kita tanpa harus membeli peralatan tambahan, misalnya hardisk dll. Kita cukup menambah kapasitas yang disediakan oleh penyedia layanan cloud computing.
- Aksesibilitas, yaitu kita bisa mengakses data kapanpun dan dimanapun kita berada, asal kita terkoneksi dengan internet, sehingga memudahkan kita mengakses data disaat yang penting.
- Keamanan, yaitu data kita bisa terjamin keamanan nya oleh penyedia layanan cloud computing, sehingga bagi perusahaan yang berbasis IT, data bisa disimpan secara aman di penyedia cloud computing. Itu juga mengurangi biaya yang diperlukan untuk mengamankan data perusahaan.
- Kreasi, yaitu para user bisa melakukan/mengembangkan kreasi atau project mereka tanpa harus mengirimkan project mereka secara langsung ke perusahaan, tapi user bisa mengirimkan nya lewat penyedia layanan cloud computing.
- Kecemasan, ketika terjadi bencana alam data milik kita tersimpan aman di cloud meskipun hardisk atau gadget kita rusak
Kerugian Cloud Computing
Dengan semua kecepatan, efisiensi, dan inovasi yang datang dengan komputasi awan, tentu saja ada risiko. Keamanan selalu menjadi perhatian besar dengan cloud terutama ketika menyangkut catatan medis yang sensitif dan informasi keuangan. Sementara regulasi memaksa layanan cloud computing untuk meningkatkan keamanan dan kepatuhan mereka, hal itu tetap menjadi masalah yang berkelanjutan. Enkripsi melindungi informasi penting, tetapi jika kunci enkripsi itu hilang, data akan hilang. Server yang dikelola oleh perusahaan komputasi awan dapat menjadi korban bencana alam, bug internal, dan pemadaman listrik juga. Jangkauan geografis komputasi awan memotong dua arah: Pemadaman listrik di California dapat melumpuhkan pengguna Di New York, dan perusahaan di Texas dapat kehilangan datanya jika terjadi sesuatu yang menyebabkan penyedia yang berbasis di Maine itu mogok. Seperti halnya teknologi apa pun, ada kurva belajar untuk karyawan dan manajer. Tetapi dengan banyak orang mengakses dan memanipulasi informasi melalui satu portal, kesalahan yang tidak disengaja dapat ditransfer ke seluruh sistem.