Riwayat Data Besar dan Pertimbangan Saat Ini
Sementara istilah "big data" relatif baru, tindakan mengumpulkan dan menyimpan sejumlah besar informasi untuk analisis akhirnya sudah lama. Konsep ini mendapatkan momentum di awal 2000-an ketika analis industri Doug Laney mengartikulasikan definisi big data yang sekarang menjadi arus utama sebagai tiga V:
Volume. Organisasi mengumpulkan data dari berbagai sumber, termasuk transaksi bisnis, media sosial, dan informasi dari sensor atau data mesin-ke-mesin. Di masa lalu, menyimpannya akan menjadi masalah - tetapi teknologi baru (seperti Hadoop) telah meringankan beban.
Velocity (Kecepatan). Data mengalir dengan kecepatan yang belum pernah terjadi sebelumnya dan harus ditangani tepat waktu. Tag RFID, sensor, dan pengukuran cerdas mendorong kebutuhan untuk menangani torrent data dalam waktu yang hampir bersamaan.
Variasi. Data datang dalam semua jenis format - dari terstruktur, data numerik dalam database tradisional hingga dokumen teks tidak terstruktur, email, video, audio, data ticker saham dan transaksi keuangan.
Di SAS, kami mempertimbangkan dua dimensi tambahan dalam hal data besar:
Variabilitas. Selain kecepatan dan varietas data yang meningkat, aliran data dapat sangat tidak konsisten dengan puncak periodik. Apakah ada yang sedang tren di media sosial? Beban data puncak harian, musiman, dan yang dipicu peristiwa dapat menjadi tantangan untuk dikelola. Terlebih lagi dengan data yang tidak terstruktur.
Kompleksitas. Data saat ini berasal dari berbagai sumber, yang membuatnya sulit untuk menautkan, mencocokkan, membersihkan, dan mengubah data di seluruh sistem. Namun, penting untuk menyambungkan dan menghubungkan hubungan, hierarki, dan beberapa tautan data atau data Anda dapat dengan cepat lepas kendali.
Algoritma yang biasa digunakan dalam Big Data
1. Decision Tree
Klasifikasi sekumpulan data ke dalam kelompok yang berbeda menggunakan atribut tertentu, jalankan tes di setiap node, melalui penilaian brach, lebih lanjut membagi data menjadi dua kelompok yang berbeda, seterusnya dan seterusnya. Tes dilakukan berdasarkan data yang ada, dan ketika data baru ditambahkan, dapat diklasifikasikan ke grup yang sesuai
Klasifikasi data berdasarkan beberapa fitur, setiap kali proses menuju ke langkah berikutnya, ada cabang penilaian, dan penilaian membagi data menjadi dua, dan proses berlanjut. Ketika tes dilakukan dengan data yang ada, data baru bisa. Pertanyaan ini dipelajari oleh data yang ada, ketika ada data baru yang masuk, komputer dapat mengkategorikan data ke dalam daun kanan.

Implementasi Big Data
- Teknologi Hadoop untuk Pemantauan Kondisi Vital PasienBeberapa rumah sakit di seluruh dunia telah menggunakan Hadoop untuk membantu stafnya bekerja secara efisien dengan Big Data. Tanpa Hadoop, sebagian besar sistem layanan kesehatan hampir tidak mungkin menganalisis data yang tidak terstruktur.
 Children's Healthcare of Atlanta merawat lebih dari 6.200 anak di unit ICU mereka. Rata-rata durasi tinggal di ICU Pediatrik bervariasi dari satu bulan sampai satu tahun. Children's Healthcare of Atlanta menggunakan sensor di samping tempat tidur yang membantu mereka terus melacak kondisi vital pasien seperti tekanan darah, detak jantung dan pernafasan. Sensor ini menghasilkan data yang sangat besar, dan sistem yang lama tidak mampu untuk menyimpan data tersebut lebih dari 3 hari karena terkendala biaya storage. Padahal rumah sakit ini perlu menyimpan tanda-tanda vital tersebut untuk dianalisa. Jika ada perubahan pola, maka perlu ada alert untuk tim dokter dan asisten lain.Sistem tersebut berhasil diimplementasikan dengan menggunakan komponen ekosistem Hadoop : Hive, Flume, Sqoop, Spark, dan Impala.Setelah keberhasilan project tersebut, project berbasis Hadoop selanjutnya yang mereka lakukan adalah riset mengenai asma dengan menggunakan data kualitas udara selama 20 tahun dari EPA (Environment Protection Agency). Tujuannya: mengurangi kunjungan IGD dan rawat inap untuk kejadian terkait asma pada anak-anak.
Children's Healthcare of Atlanta merawat lebih dari 6.200 anak di unit ICU mereka. Rata-rata durasi tinggal di ICU Pediatrik bervariasi dari satu bulan sampai satu tahun. Children's Healthcare of Atlanta menggunakan sensor di samping tempat tidur yang membantu mereka terus melacak kondisi vital pasien seperti tekanan darah, detak jantung dan pernafasan. Sensor ini menghasilkan data yang sangat besar, dan sistem yang lama tidak mampu untuk menyimpan data tersebut lebih dari 3 hari karena terkendala biaya storage. Padahal rumah sakit ini perlu menyimpan tanda-tanda vital tersebut untuk dianalisa. Jika ada perubahan pola, maka perlu ada alert untuk tim dokter dan asisten lain.Sistem tersebut berhasil diimplementasikan dengan menggunakan komponen ekosistem Hadoop : Hive, Flume, Sqoop, Spark, dan Impala.Setelah keberhasilan project tersebut, project berbasis Hadoop selanjutnya yang mereka lakukan adalah riset mengenai asma dengan menggunakan data kualitas udara selama 20 tahun dari EPA (Environment Protection Agency). Tujuannya: mengurangi kunjungan IGD dan rawat inap untuk kejadian terkait asma pada anak-anak. - Valence health : peningkatan kualitas layanan dan reimbursementsValence health menggunakan Hadoop untuk membangun data lake yang merupakan penyimpanan utama data perusahaan. Valence memproses 3000 inbound data feed dengan 45 jenis data setiap harinya. Data kritikal ini meliputi hasil tes lab, data rekam medis, resep dokter, imunisasi, obat, klaim dan pembayaran, serta klaim dari dokter dan rumah sakit, yang digunakan untuk menginformasikan keputusan dalam peningkatan baik itu pendapatan ataupun reimbursement. Pertumbuhan jumlah klien yang pesat dan peningkatan volume data terkait semakin membebani infrastruktur yang ada.
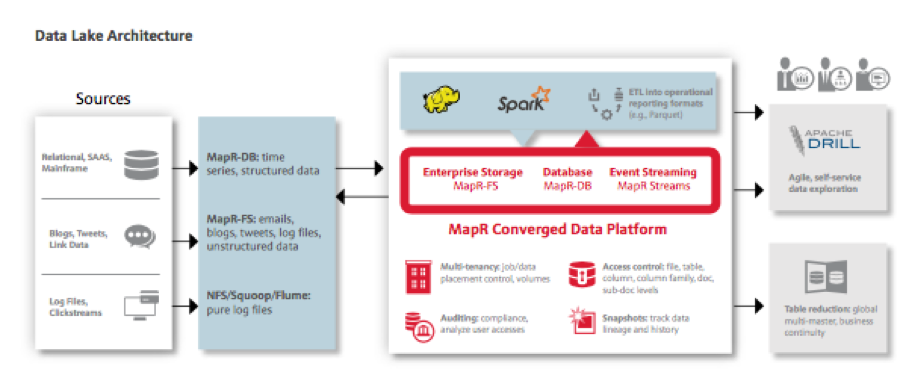 Sebelum menggunakan big data, mereka membutuhkan waktu hingga 22 jam untuk memproses 20 juta records data hasil laboratorium. Penggunaan big data memangkas waktu siklus dari 22 jam menjadi 20 menit, dengan menggunakan hardware yang jauh lebih sedikit. Valence Health juga mampu menangani permintaan pelanggan yang sebelumnya sulit untuk diselesaikan. Misalnya jika seorang klien menelpon dan mengatakan bahwa ia telah mengirimkan file yang salah 3 bulan yang lalu, dan perlu untuk menghapus data tersebut. Sebelumnya dengan solusi database tradisional, mereka memerlukan 3 sampai 4 minggu. Dengan memanfaatkan MapR snapshot yang menyediakan point-in-time recovery, Valence dapat melakukan roll-back dan menghapus file tersebut dalam hitungan menit.
Sebelum menggunakan big data, mereka membutuhkan waktu hingga 22 jam untuk memproses 20 juta records data hasil laboratorium. Penggunaan big data memangkas waktu siklus dari 22 jam menjadi 20 menit, dengan menggunakan hardware yang jauh lebih sedikit. Valence Health juga mampu menangani permintaan pelanggan yang sebelumnya sulit untuk diselesaikan. Misalnya jika seorang klien menelpon dan mengatakan bahwa ia telah mengirimkan file yang salah 3 bulan yang lalu, dan perlu untuk menghapus data tersebut. Sebelumnya dengan solusi database tradisional, mereka memerlukan 3 sampai 4 minggu. Dengan memanfaatkan MapR snapshot yang menyediakan point-in-time recovery, Valence dapat melakukan roll-back dan menghapus file tersebut dalam hitungan menit. - Hadoop dalam Pengobatan Kanker dan GenomicsSalah satu alasan terbesar mengapa kanker belum dapat dibasmi sampai sekarang adalah karena kanker bermutasi dalam pola yang berbeda dan bereaksi dengan cara yang berbeda berdasarkan susunan genetik seseorang. Oleh karena itu, para peneliti di bidang onkologi menyatakan bahwa untuk menyembuhkan kanker, pasien perlu diberi perawatan yang disesuaikan dengan jenis kanker berdasarkan genetika masing-masing pasien.Ada sekitar 3 miliar pasangan nukleotida yang membentuk DNA manusia, dan diperlukan sejumlah besar data untuk diorganisir secara efektif jika kita ingin melakukan analisis. Teknologi big data, khususnya Hadoop dan ekosistemnya memberikan dukungan yang besar untuk paralelisasi dan proses pemetaan DNA.David Cameron, Perdana Menteri Inggris telah mengumumkan dana pemerintah sebesar £ 300 juta pada bulan Agustus, 2014 untuk proyek 4 tahun dengan target memetakan 100.000 genom manusia pada akhir tahun 2017 bekerja sama dengan perusahaan Bioteknologi Amerika Illumina dan Genomics Inggris. Tujuan utama dari proyek ini adalah memanfaatkan big data dalam dunia kesehatan untuk mengembangkan personalized medicine bagi pasien kanker.Arizona State University mengadakan sebuah proyek penelitian yang meneliti jutaan titik di DNA manusia untuk menemukan variasi penyebab kanker sedang berlangsung. Proyek ini merupakan bagian dari Complex Adaptive Systems Initiative (CASI), yang mendorong penggunaan teknologi untuk menciptakan solusi bagi permasalahan dunia yang kompleks.Dengan menggunakan Apache Hadoop, tim peneliti universitas dapat memeriksa variasi dalam jutaan lokasi DNA untuk mengidentifikasi mekanisme kanker dan bagaimana jaringan berbagai gen mendorong kecenderungan dan efek kanker pada individu."Proyek kami memfasilitasi penggunaan data genomik berskala besar, sebuah tantangan bagi semua institusi penelitian yang menangani pecision medicine," kata Jay Etchings, direktur komputasi riset ASU. Ekosistem Hadoop dan struktur data lake terkait menghindarkan setiap peneliti dan pengguna klinis untuk mengelola sendiri jejak data genomik yang besar dan kompleks.
- UnitedHealthcare: Fraud, Waste, and AbuseSaat ini setidaknya 10% dari pembayaran asuransi Kesehatan terkait dengan klaim palsu. Di seluruh dunia kasus ini diperkirakan mencapai nilai miliaran dolar. Klaim palsu bukanlah masalah baru, namun kompleksitas kecurangan asuransi tampaknya meningkat secara eksponensial sehingga menyulitkan perusahaan asuransi kesehatan untuk menghadapinya.UnitedHealthCare adalah sebuah perusahaan asuransi yang memberikan manfaat dan layanan kesehatan kepada hampir 51 juta orang. Perusahaan ini menjalin kerja sama dengan lebih dari 850.000 orang tenaga kesehatan dan sekitar 6.100 rumah sakit di seluruh negeri. Payment Integrity group/divisi integritas pembayaran mereka memiliki tugas untuk memastikan bahwa klaim dibayar dengan benar dan tepat waktu. Sebelumnya pendekatan mereka untuk mengelola lebih dari satu juta klaim per hari (sekitar 10 TB data tiap harinya) bersifat ad hoc, sangat terikat oleh aturan, serta terhambat oleh data yang terpisah-pisah. Solusi yang diambil oleh UnitedHealthCare adalah pendekatan dual mode, yang berfokus pada alokasi tabungan sekaligus menerapkan inovasi untuk terus memanfaatkan teknologi terbaru.Dalam hal pengelolaan tabungan, divisi tersebut membuat “pabrik” analisis prediktif di mana mereka mengidentifikasi klaim yang tidak akurat secara sistematis dan tepat. Saat ini Hadoop merupakan data framework berplatform tunggal yang dilengkapi dengan tools untuk menganalisa informasi dari klaim, resep, plan peserta, penyedia layanan kesehatan yang dikontrak, dan hasil review klaim terkait.Mereka mengintegrasikan semua data dari beberapa silo di seluruh bisnis, termasuk lebih dari 36 aset data. Saat ini mereka memiliki banyak model prediktif (PCR, True Fraud, Ayasdi, dll.) yang menyediakan peringkat provider yang berpotensi melakukan kecurangan, sehingga mereka dapat mengambil tindakan yang lebih terarah dan sistematis.
- Liaison Technologies: Streaming System of Record for HealthcareLiaison Technologies menyediakan solusi berbasis cloud untuk membantu organisasi dalam mengintegrasikan, mengelola, dan mengamankan data di seluruh perusahaan. Salah satu solusi vertikal yang mereka berikan adalah untuk industri kesehatan dan life science, yang harus menjawab dua tantangan : memenuhi persyaratan HIPAA dan mengatasi pertumbuhan format dan representasi data.Dengan MapR Stream, permasalahan data lineage dapat terpecahkan karena stream menjadi sebuah SOR (System of Record) dengan berfungsi sebagai log yang infinite dan immutable dari setiap perubahan data. Tantangan kedua, yaitu format dan representasi data, bisa digambarkan dengan contoh berikut: rekam medis pasien dapat dilihat dengan beberapa cara yang berbeda (dokumen, grafik, atau pencarian) oleh pengguna yang berbeda, seperti perusahaan farmasi, rumah sakit, klinik, atau dokter.Dengan melakukan streaming terhadap perubahan data secara real-time ke basis data, grafik, dan basis data MapR-DB, HBase, MapR-DB JSON, pengguna akan selalu mendapatkan data paling mutakhir dalam format yang paling sesuai.
Tidak ada komentar:
Posting Komentar